
 초보몽키의 개발공부로그
초보몽키의 개발공부로그
강의노트 06. ASCII, UNICODE, utf8
05 Apr 2017 |패스트캠퍼스 컴퓨터공학 입문 수업을 듣고 중요한 내용을 정리했습니다. 개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
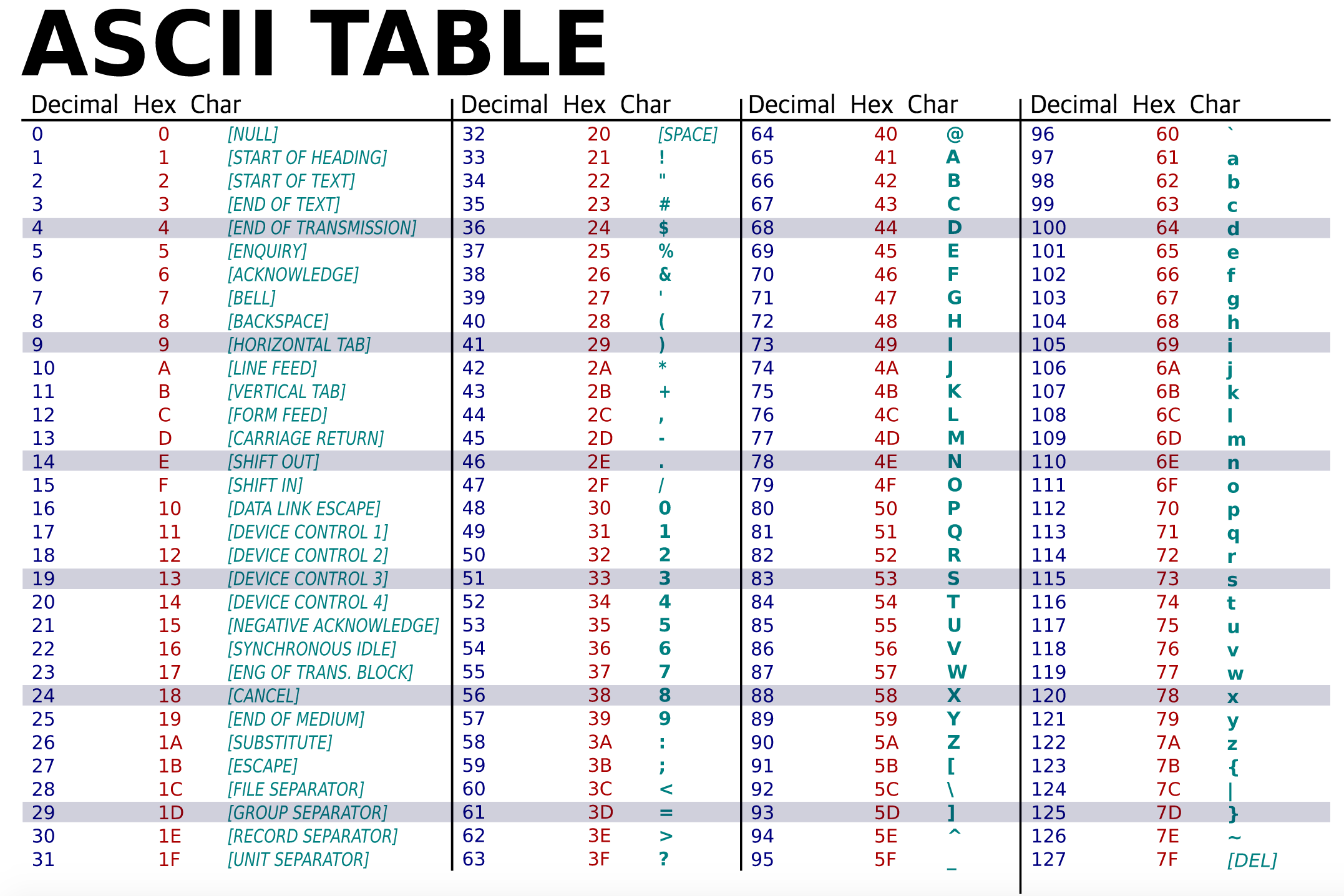
아스키코드 (ASCII)
- 7bit (2의 7승 : 128 가지 문자)
- American Standard Code for Information Interchange
- 컴퓨터의 기본 저장 단위는 바이트(byte)이고, 1byte는 8bit이다.
1byte에는 2의 8승에 해당하는 256개의 고유한 값을 저장할 수 있다.아스키코드는 7비트로 128개의 고유한 값을 저장한다. (문자 하나당 숫자 하나를 매핑, 1비트는 별도의 목적을 위해서 사용)- 로마자 및 특수 기호(한글 포함 안됨)
유니코드 (UNICODE)
- 2byte (2의 16승 : 65,536가지 문자)
- 한글은 자음과 모음의 조합 개수만해도 128개를 넘는다.
- 이와 같이 7bit ASCII 코드에 담을 수 없는 문자를 정의하기 위해서
2byte 국제표준코드 유니코드가 등장하였다. 2byte는 16bit로 2의 16승 약 6만 5천개의 문자를 저장할 수 있다.- 유니코드로 ASCII 코드를 포용 가능하다.
유니코드 확인
- ‘A’ - U+0041 ( = ASCII ‘A’ 는 16진수로 41)
- (참고) 파이썬에서 유니코드 확인하기
>>> '\u0041'
>>> 'A'
>>> '\uAC00'
>>> '가'
UTF-8
- 유니코드 부호화 방식 (8bit 기반 )
가변 길이 유니코드 인코딩 시스템- 특정 문자 집합 안의 문자들을 컴퓨터 시스템 안헤서 사용할 목적으로 일정한 범위 안의 정수 (코드값) 들로 변환하는 방법
- ASCII 코드의 언어는 1byte로 나타내며, 한글의 경우 3byte로 나타낸다.
utf-8 탄생 배경
- 유니코드를 사용하면 영어권 사용자들은 메모리 낭비가 2배가 된다. (영어는 1byte ascii로 충분하기 때문에)
- 유니코드는 2byte로 규약을 했으나 메모리에 저장하고, 네트워크에 통신 할 때 한번 걸러서 저장을 한다 (부호화 : encoding)
- 0~127 사이에 존재하는 모든 코드 포인트(ASCII)들을 1byte로 저장
- 128 이상인 것은 2byte, 3byte로 저장한다. (한글은 3byte)
파이썬의 기본 부호화 방식 utf8
>>> coded = "abcde".encode()
>>> coded
b abcde
>>> for i in coded_string:
print(i)
97
98
99
100
101
>>> coded_string = "파이썬".encode()
>>> coded_string
b'\xed\x8c\x8c\xec\x9d\xb4\xec\x8d\xac' # 한 글자당 3byte
>>> coded.decode()
'파이썬'