초보몽키의 개발공부로그
초보몽키의 개발공부로그
강의노트 17. 알고리즘, 자료구조 개요
17 Apr 2017 |패스트캠퍼스 컴퓨터공학 입문 수업을 듣고 중요한 내용을 정리했습니다. 개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
자료구조와 알고리즘
- 프로그래밍에서 데이터를 구조적으로 표현하는 방식과 이를 구현하는 데 필요한 알고리즘에 대해 논하는 기초이론
- 효율적인 자료구조란 프로그램의 실행시간 효율과 저장공간 효율을 의미한다. (효과적으로 설계된 자료구조는 실행시간 혹은 메모리 용량과 같은 자원을 최소한으로 사용하면서 연산을 수행하도록 해준다.)
- 각 자료구조의 장단점을 숙지하고 상황별로 적합한 자료구조를 선택하는 능력이 중요하다.
- 자료구조 : 데이터를 어떤 구조로 저장하고, 탐색하고, 삭제해야 가장 효율적일까? (어떻게 메모리를 가장 효율적으로 사용할 수 있을까? -> 실행속도 영향)
- 알고리즘 : 문제를 해결하는 방법론
- 참고 - 자료구조 위키백과
알고리즘
알고리즘 이란 어떤 값을 입력으로 받아 원하는 값으로 출력하는 잘 정의된 계산 절차 를 말한다. 따라서 알고리즘은 어떤 입력을 어떤 출력으로 변환하는 일련의 계산 과정이라 할 수 있다.
자료구조
자료구조 란 데이터에 편리하게 접근하고, 변경하기 위해서 데이터를 저장하거나 조직하는 방법 을 말한다.
모든 목적에 맞는 자료구조는 없다. 따라서 각 자료구조가 갖는 장점과 한계를 잘 아는 것이 중요하다.
자료구조는 언어별로 지원하는 양상이 다르다. 따라서 각각의 언어가 가진 자료구조의 사용방법도 중요하지만, 무엇보다 각 자료구조의 본질과 컨셉을 이해하는 것 이 중요하다. 컨셉을 알고 있다면 기억해야 할 것이 현저히 줄어들게 된다.
자료구조의 미션 : 메모리의 효율적인 사용
- 컴퓨터에는 3가지 중요한 부품이 존재하며 다음과 같은 특성을 가진다.
- CPU : 중앙정보처리장치, 레지스터, 데이터를 연산/처리하는 가장 중요한 부분, 아주 빠름 (기억 떠올리기)
- 메모리 : RAM(Random Access Memory), CPU에서 직접 접근이 가능, 사용자가 자유롭게 내용을 읽고 쓰고 지울 수 있다. 휘발성 기억장치, 빠름 (책에서 특정한 내용 찾아 읽기)
- 스토리지 : HDD, SSD, 비휘발성 기억장치, 용량이 아주 크지만 느림 (지구를 한바퀴 돌아서 찾기)
- 상기와 같은 이유로 데이터는 기본적으로 스토리지에 저장된다.
- 하지만 스토리지는 매우 느리기 때문에 CPU와 함께 일하기에는 속도면에서 부족하다.
- 따라서 어떤 프로그램을 실행하면 해당 프로그램과 데이터는 메모리로 옮겨진다.
- CPU는 메모리에 로드된 데이터를 이용해서 여러가지 일을 하게 된다.
- 그러므로 실행속도를 결정하는 것은 대체로
메모리이며, 자료구조를 배우는 이유는메모리의 효율적인 사용이라고 할 수 있다.
자료구조와 알고리즘의 관계
- 자료구조를 구현하기 위해서 알고리즘이 필요하다.
- 자료구조의 알고리즘 : 데이터를 저장하고 탐색하는 방법에 대한 고민들
- 자료구조를 이용한 알고리즘 : 자료구조를 활용하여 어떤 문제를 해결하는 것
자료구조의 구성
- Insert : 데이터를 어떻게 저장 할 것인가
- Search : 데이터를 어떻게 탐색 할 것인가
- Delete : 데이터를 어떻게 삭제 할 것인가
자료구조의 분류
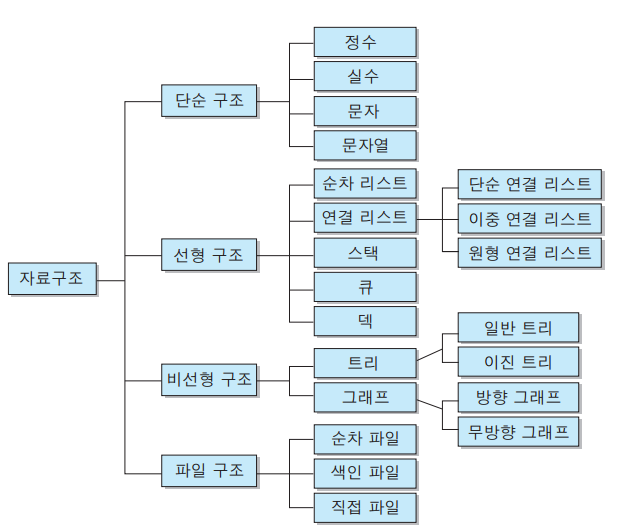
- 단순구조 : 프로그래밍에서 사용되는 기본 데이터 타입
- 선형구조 : 저장되는 자료의 전후관계가 1:1 (리스트, 스택, 큐 등)
- 비선형구조 : 데이터 항목 사이의 관계가 1:n 또는 n:m (트리, 그래프 등)
- 파일구조 : 서로 관련된 필드들로 구성된 레코드의 집합인 파일에 대한 자료구조